UCAS CTF
扩展:计算机中的程序运行时栈
Author: doyo
回顾一下之前讲的C语言基础部分,你有没有思考过这些问题:
- 执行函数时,计算机怎么知道传递的参数是什么呢?
- 函数执行结束时,计算机怎么知道该回到哪里继续执行呢?
- 局部变量保存在哪里?计算机怎么确保它只在代码的局部生效?
上述这些问题,都与计算机中的程序运行时栈有关。
基本概念
程序运行时栈(runtime stack),指的是计算机为每个程序分配的一块特殊的内存区域。这块区域按照栈的方式组织,并且可以通过计算机硬件提供的寄存器(一般名为sp,stack pointer)进行访问。一般情况下,在讨论汇编语言和操作系统时,我们提到的栈都指的是它。
下文我们以x86架构为例,讲解程序运行时栈在程序运行过程中的重要作用。
x86中的程序运行时栈
在x86中,与程序运行时栈有关的寄存器有两个:指向栈顶的sp和指向栈底的bp(base pointer)。sp和bp是两个16位的寄存器,现在已不太常用(因为目前主流的计算机已经是64位的了),更常用的是32位的esp/ebp或64位的rsp/rbp。这里的前缀e表示extended,而r表示register,按x86的命名规律,带有前缀e的是32位寄存器,而带有前缀r的是64位寄存器。
在x86架构中,一个程序所使用的内存区域大致被划分为以下几个部分:
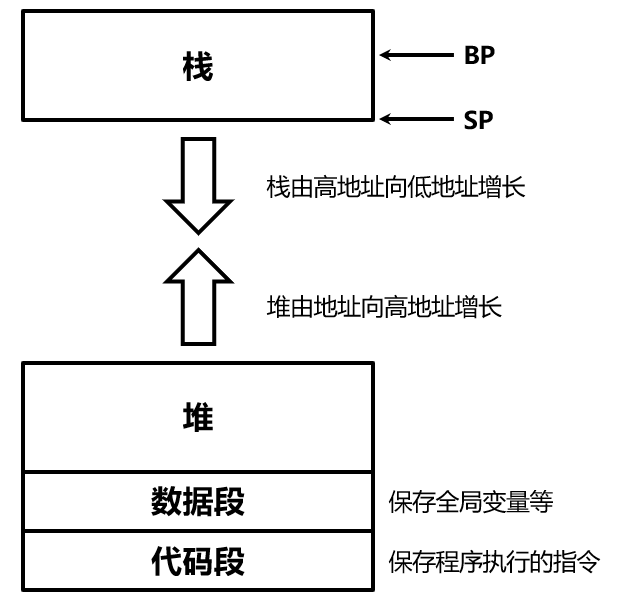
注意,x86架构中,比较反直觉的是,栈一般是从高地址向低地址增长的,也是说,栈顶在低地址而栈底在高地址。
压栈与弹栈的指令
与栈相关的指令主要有两条:
- push:这条指令将一个寄存器中的数值或一个立即数(即一个常量)或内存中某个地址处存放的数据存入栈中,例如:
push eax
这条指令将寄存器eax中的数据存入栈中。具体过程如下:首先,esp = esp - 4(因为eax是32位的寄存器,它存放的数据占用4个字节),esp指向当前栈顶元素前面的单元(这样它就是新的栈顶);然后,将eax中的数据送入esp指向的单元。
- pop:这条指令弹出栈顶元素,并将其送入指定的寄存器中,例如:
pop eax
这条指令将栈顶元素出栈并放入寄存器eax中。具体过程如下:首先,将esp指向的内存单元处的数据送入eax中;然后esp = esp + 4,这样esp就指向了新的栈顶。可以发现,pop eax的执行过程正好与push eax相反。
push和pop指令还有很多变体,但归根结底都是将数据进栈出栈,只是操作的对象不同而已。
函数调用的具体过程
我们来研究一个实例。
下面的代码给出了一个简单的、带函数调用的程序test.c(点击此处可以下载源代码):
int x = 1, y = 3;
int work(int a, int b) {
int c;
c = a + b;
return c;
}
int main() {
work(x, y);
return 0;
}
用如下指令编译可以得到汇编程序(完整汇编程序详见此处(点击下载)):
gcc test.c -m32 -S -o test.S
这里的-m32选项表示编译成32位的汇编程序;-S选项表示仅生成汇编代码,而不生成最终的二进制可执行程序。所以这条指令执行后,我们得到的test.S是一个不可执行的、32位的汇编代码。
我们现在来阅读一下得到的汇编代码test.S(为了便于阅读,此处展示的代码删去了CFI保护相关的代码)(这里采用的是AT&T语法,源操作数写在目的操作数之前):
work:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl 8(%ebp), %edx
movl 12(%ebp), %eax
addl %edx, %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
leave
ret
main:
pushl %ebp
movl %esp, %ebp
call __x86.get_pc_thunk.ax
addl $_GLOBAL_OFFSET_TABLE_, %eax
movl y@GOTOFF(%eax), %edx
movl x@GOTOFF(%eax), %eax
pushl %edx
pushl %eax
call work
addl $8, %esp
movl $0, %eax
leave
ret
首先从main()函数开始,我们发现,在它的前两行,我们将ebp压栈,并且把esp的值赋给了ebp:
main:
pushl %ebp ; pushl中的l表示是对32位的数据进行操作
movl %esp, %ebp ; mov指令就相当于是C语言中的赋值语句,这条指令相当于是ebp = esp
在这里似乎还看不出它们有什么作用,没关系,我们把它们先放一放,继续往后看:
call __x86.get_pc_thunk.ax
addl $_GLOBAL_OFFSET_TABLE_, %eax
movl y@GOTOFF(%eax), %edx ; 把变量y存入寄存器edx中
movl x@GOTOFF(%eax), %eax ; 把变量x存入寄存器eax中
这四条指令的作用是从内存中读取我们声明的变量x和y,把它们存入寄存器中,以便进行接下来的操作:
pushl %edx
pushl %eax
call work ; 调用work()函数
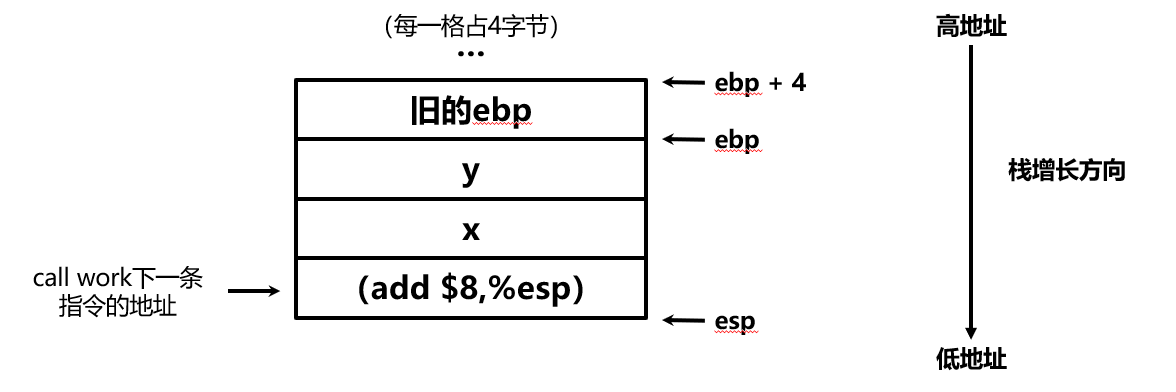
我们发现,变量x和y的值被压入了栈中(顺序是先y后x);然后,我们通过call指令调用了work()函数。回忆一下C代码中调用work()函数的方式,你可能已经猜到了这两条push指令的作用:传递参数;而call指令,它的作用就是像C语言的goto语句那样跳转到指定的标号处。但call指令还有一个隐含的作用:将它下一条指令的地址(此处即”addl $8, %esp”的地址)压入栈中。所以,这条call指令的作用相当于:
pushl (addl $8, %esp) ; 我们用()表示取地址
goto work
在上面这些指令指向结束之后,栈中的内容变成了:
现在,让我们把目光转向work()函数,我们在前两行发现了似曾相识的指令:
work:
pushl %ebp
movl %esp, %ebp
现在你或许意识到了,这两行指令是几乎所有函数被调用时都会执行的指令。它们的作用在于创建一个新的堆栈帧(stack frame),即堆栈上一片保留的区域,ebp指向的便是这个堆栈帧的底部,esp指向的是这个堆栈帧的顶部。
接着向下看:
subl $16, %esp
这条指令将esp减去16。它的作用在栈上为我们创建的局部变量预留空间。你也许注意到了,我们创建的局部变量c是int类型的,只占4个字节,但这里减去的是16而不是4,这是因为在我使用的编译环境中(gcc version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04.2) )内存是按16字节对齐的,所以它总是按16字节的倍数来为局部变量预留空间。此处实际使用的只有4个字节。
接下来,我们将两个参数相加,并把结果赋给局部变量c:
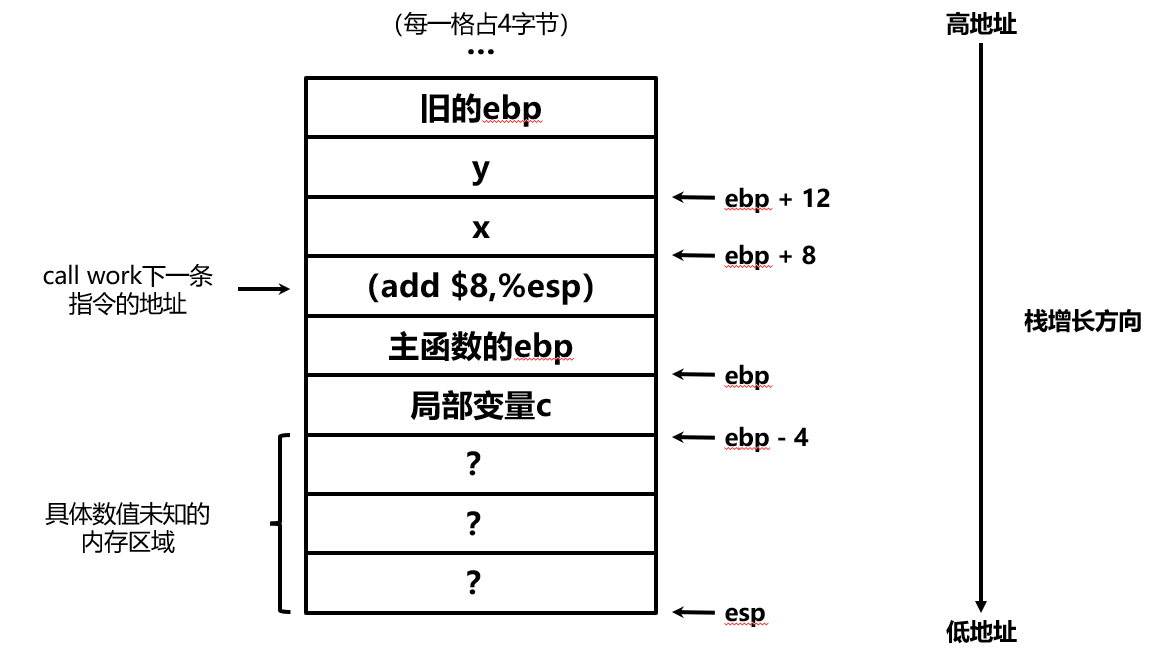
movl 8(%ebp), %edx ; 取出参数x
movl 12(%ebp), %eax ; 取出参数y
addl %edx, %eax ; 加法指令,结果保存在目的寄存器(在这里使用的AT&T语法中,是最后一个寄存器)中
movl %eax, -4(%ebp) ; 结果存入局部变量c
我们如何在栈上找到参数和局部变量呢?答案是通过ebp加上偏移量。这也是为什么ebp被称作栈基指针,因为它是我们访问栈中数据的一个“基准”。上述代码执行完成后,栈中的内容变成了:
现在work()函数的工作完成了,我们要返回主函数。这三条指令完成了这样的操作:
movl -4(%ebp), %eax ; 将返回结果存放在eax中
leave ; 平衡栈,相当于"mov %ebp, %esp"和"pop %ebp",这样我们就回到了主函数的栈帧
ret ; 返回栈
这三条指令对应于C代码中的“return c;”语句。首先,局部变量c作为work()函数的返回值,需要传递给调用它的主函数;在x86架构中,大部分情况下我们采用ax/eax/rax来传递函数的返回值,所以上面的第一条指令作用在于传递函数返回值。其次,我们为work()函数创建了一个新的栈帧,在其中保存了work()函数使用的局部变量;显然,这些局部变量在返回主函数后是不能再使用的,所以我们要用leave指令来关闭它的栈帧,这一操作也称为平衡栈(有借有还,再借不难)。最后我们通过ret指令返回主函数,它的作用在于从栈中弹出执行work()函数后下一条指令的地址,并让程序跳转到那里继续执行。所以,接下来执行的指令是
addl $8, %esp
这条指令仍然在平衡栈。这是因为我们在调用work()函数时还用栈传递了两个32位的参数,这里要把它们的空间还回去。
现在,主函数的工作也完成了,我们要用类似的方式退出:
movl $0, %eax
leave
ret
(仔细思考函数调用的具体过程,也许你会发现,其中埋藏了一个巨大的隐患,你意识到了吗?)
总结:函数调用的过程
我们现在可以将函数调用的过程概括如下:
- 如果有被传递的参数,则将其压入堆栈(压栈顺序与C语言顺序相反)
- 当子程序被调用时,将该子程序返回的地址压入堆栈
- 子程序开始执行时,将ebp压入堆栈
- 设置ebp等于esp。从这时起,ebp变成了该子程序所有参数的引用基址
- 如果有局部变量,修改esp以便在堆栈中为这些变量预留空间
- 如果需要保存寄存器,则将它们压入堆栈
相应的,在函数调用结束时,具体过程如下:
- 如果有返回值,通常将其放入eax中
- 从堆栈中删除局部变量(平衡栈)
- 从堆栈中弹出调用该子程序前的ebp
- 用ret指令返回
- 平衡栈
小结
我们现在可以回答开头提出的三个问题了:
-
执行函数时,计算机怎么知道传递的参数是什么呢?
我们把参数放到栈上,让计算机从栈上取,这种方式称为栈传参。不过,现在很多计算机已经不再采用这种方式,而是改用寄存器传参了(比如当你在编译test.c时去掉-m32选项,你会发现得到的汇编程序中,x和y是通过edi和esi传递的)。
-
函数执行结束时,计算机怎么知道该回到哪里继续执行呢?
在调用函数时,我们把返回地址保存在栈上,然后在函数执行结束时,我们再从栈中取出返回地址,让程序从调用函数的下一条指令继续执行。
-
局部变量保存在哪里?计算机怎么确保它只在代码的局部生效?
我们把局部变量保存在栈上。当函数结束时,我们关闭这个函数的栈帧,从而使这个局部变量失效。